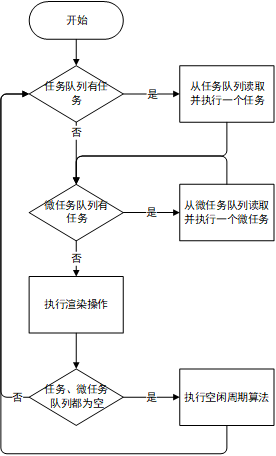
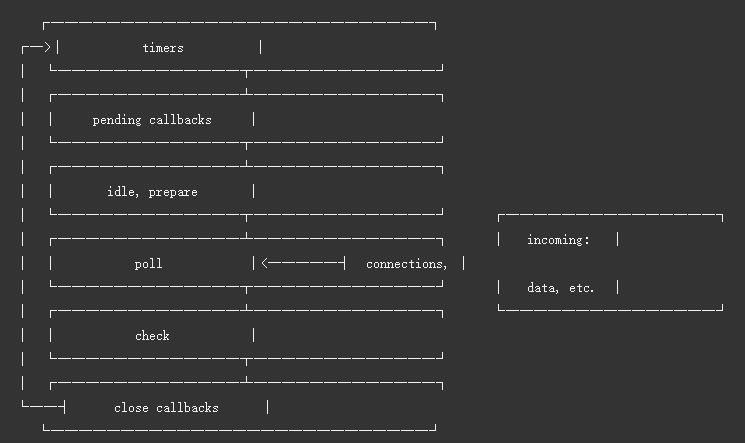
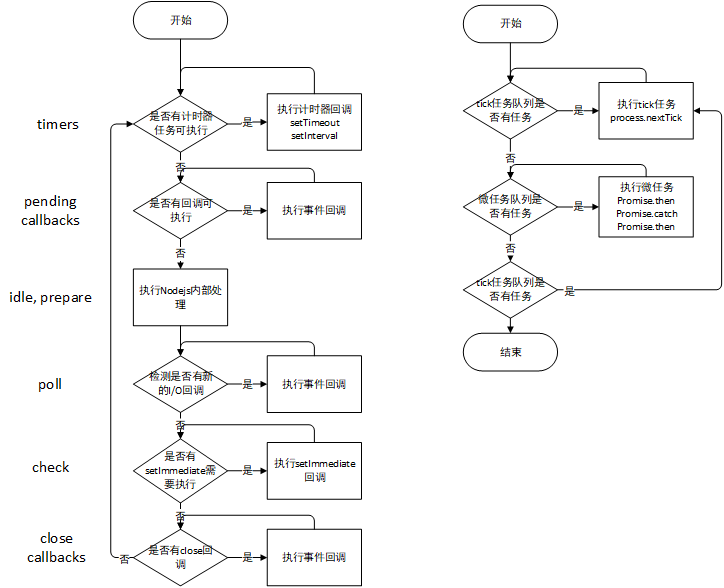
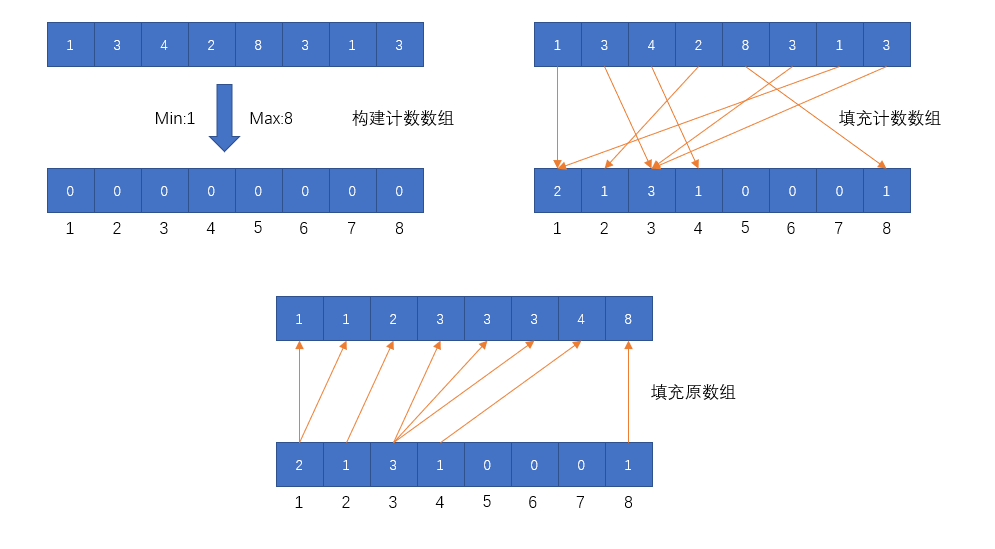
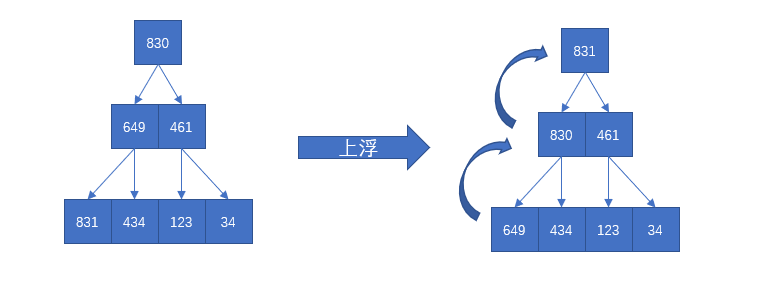
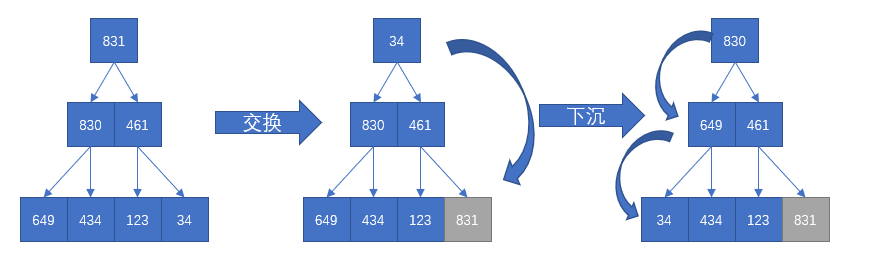
functionCountSort(arr){ let min = Infinity let max = 0 let len = arr.length for (let i = 0; i < len; i++){ if (arr[i] < min) min = arr[i] if (arr[i] > max) max = arr[i] }
let countarr = newArray(max - min + 1).fill(0)
for (let i = 0; i < len; i++){ countarr[arr[i] - min]++ }
let p = 0 for (let i = 0; i <= max - min; i++){ for (let j = 0; j < countarr[i]; j++){ arr[p] = i + min p++ } }
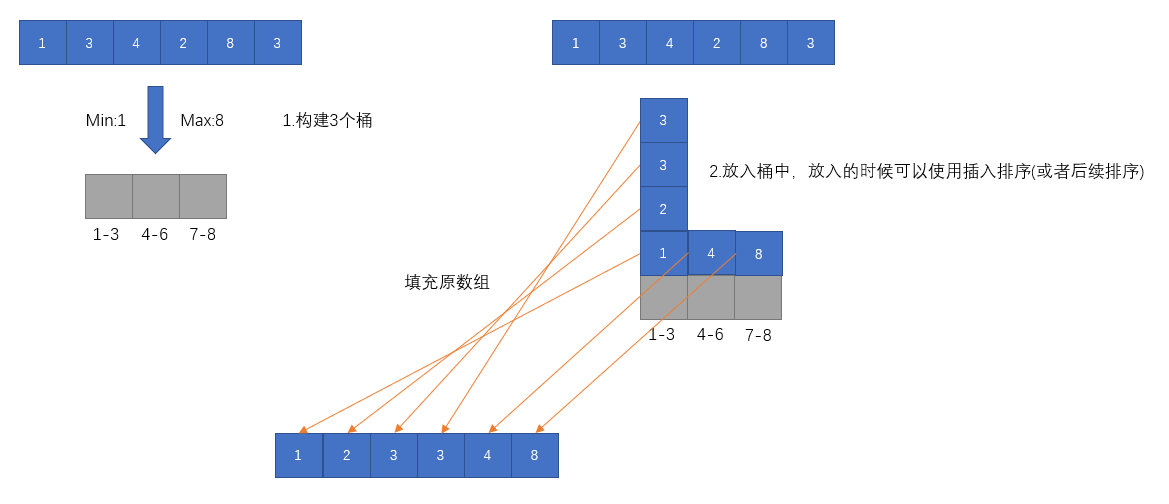
functionBucketSort(arr, bukectSize = 10){ let min = Infinity let max = 0 let len = arr.length for (let i = 0; i < len; i++){ if (arr[i] < min) min = arr[i] if (arr[i] > max) max = arr[i] }
let bucketNum = parseInt((max - min) / bukectSize) + 1 let buckets = newArray(bucketNum).fill(0).map(_ =>newArray())
for (let i = 0; i < len; i++){ let b = parseInt((arr[i] - min) / bukectSize) let bucket = buckets[b] let len = bucket.length bucket[len] = arr[i] for (let j = len - 1; j >= 0; j--){ if (bucket[j] < arr[i]){ bucket[j + 1] = bucket[j] } else { bucket[j + 1] = arr[i] break } } }
let p = 0 for (let i = 0; i < buckets.length; i++){ for (let j = 0; j < buckets[i].length; j++){ arr[p] = buckets[i][j] p++ } }