这里从排序算法开始说起,排序算法是很常见的需求,虽然在编程当中,排序大多使用已经封装好的函数,但还是需要深入了解一下
选择排序
排序当中,最容易理解和简单的就是选择排序了,算法就是首先在数组中找到最小的元素,然后将它与数组的第一个元素交换位置,接下来在剩下的元素中重复操作,直到完成排序
1 | function selectSort(arr){ |
算法属性
| 最优时间复杂度 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| Ω(n2) | Θ(n2) | O(n2) | O(1) | 不稳定 |
在这里有个稳定性的属性,稳定性指的是如果a=b,a初始在b的前面,那么排序完成后a依然在b的前面,如果不能保证a还是在b的前面,那么就是不稳定的
通过算法可以很容易看出,需要执行的操作都是稳定在1+2+3...+(n-1),也就是n2/2,无论数据如何都是这样,而排序算法由于不是挨着交换,就可能导致跳过中间相等的元素,所以结果是不稳定的
插入排序
插入排序也想对很好理解,就是一个个的插入到合适的位置当中,就和拿扑克牌一样,算法就是从没有排好顺序的剩余数据中选择第一个,然后在已经排好顺序的数据中,从后向前查找,找到比它小的数据的时候,将其插入到这个数据的后面,后面的数据的位置整体+1
1 | function insertSort(arr){ |
算法属性
| 最优时间复杂度 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| Ω(n) | Θ(n2) | O(n2) | O(1) | 稳定 |
这个的平均时间复杂度和最差复杂度很容易看出来是O(n2)级别的,当数据就是排好序的时候,就不需要交换就处理完了
冒泡排序
冒泡排序和插入排序有些相似,所以常常被弄的很迷糊,冒泡排序同样也是一个个的选入然后放入排好序的队列当中,但是不想插排那样遍历找到合适的位置插入,而是和相邻的元素交换,知道前面的元素比自己大,这样一个个的向前交互的过程,就像一个个的泡泡上冒,说以叫做冒泡排序
1 | function bubbleSort(arr){ |
算法属性
| 最优时间复杂度 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| Ω(n) | Θ(n2) | O(n2) | O(1) | 稳定 |
冒泡的编码相对于插排来说要简单的多,但是由于需要挨个挨个的交换,这个会浪费大量的性能,所以大多采用插排而不是冒泡
希尔排序
希尔排序是一种基于插入排序的改进算法,在插入算法中,每个元素都需要从最后慢慢的遍历到前面来查找合适的位置,但是在数据量极大的时候,如果一个元素的位置很考前,那么就会遍历很久才能找到合适的位置,希尔排序的目标就是加速这一个过程,从而实现加速
希尔排序的思想是让数组中的数据在一定间隔h上是有序的,这样的数组被称为h有序数组,也就是说将h有序数组的元素,从任意位置上取出间隔h的数据组成的数组是有序的,希尔排序便是将数组从一个很大的h来排序,然后递减知道h=1就完成了排序,而希尔排序中用的h的递增数列是有相关研究的,有的算法会自动生成序列,有的则在外部存储了固定的序列,来加速
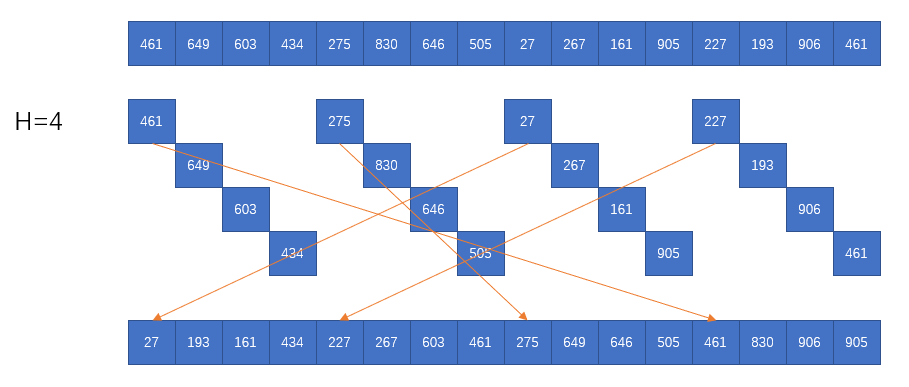
1 | function shellSort(arr){ |
算法属性
| 最优时间复杂度 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| Ω(n) | Θ(n1.3) | O(n2) | O(1) | 不稳定 |
希尔排序在面对大数据量的时候,优势更加明显
END
2019-02-22 立项
2019-02-10 立项