快速排序是目前应用最广泛的排序算法,实现简单,而且对应各种不同的输入数据都有良好的性能,这篇文章就是介绍一下快速排序的实现
快速排序
快速排序和归并排序有互通之处,都是使用了分治的思想,归并排序是将大数组分为两个小数组,当两个小数组排序好了以后,再进行合并,而快速排序则是将大数组以某个中间值分为两个数组,当两个小数组都有序,那么大数组也就有序了
一般都是取数组的第一个元素来做拆分,然后递归向下拆分、排序,最终实现
1 | function fastSort(arr, start = 0, end = arr.length - 1){ |
数组切分
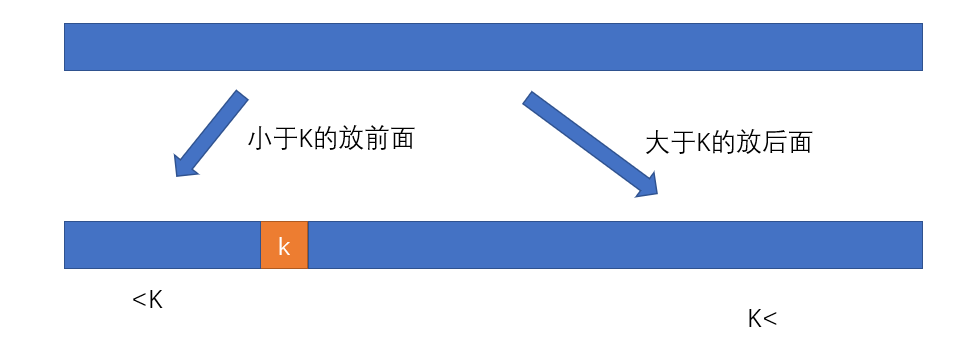
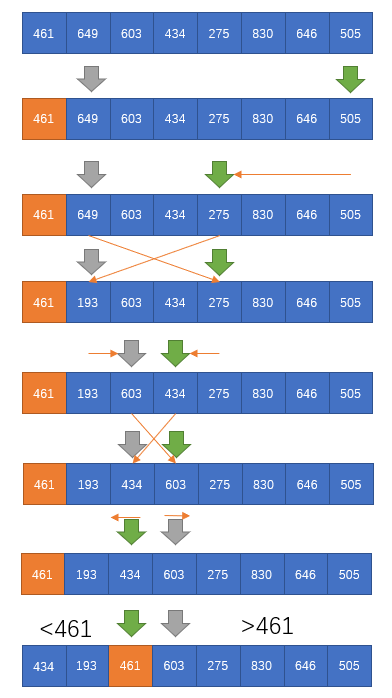
在快速排序中,数组的切分是比较核心的一部分,在通常算法下,都是选取切分部分的第一个元素作为切分的中间值,使用两个标记,一个从左到右,一个从右到左,左边的标记在寻到大于中间值的元素后停下,与右边的标记寻到的小于中间值的位置数据进行交换,循环下去,知道两个标记相遇
算法改进
小数组使用插入排序
这一点和归并排序相同,在数组较小时,递归的性能消耗较大,可以使用插排、选排这些算法对小数组进行排序
三取样切分
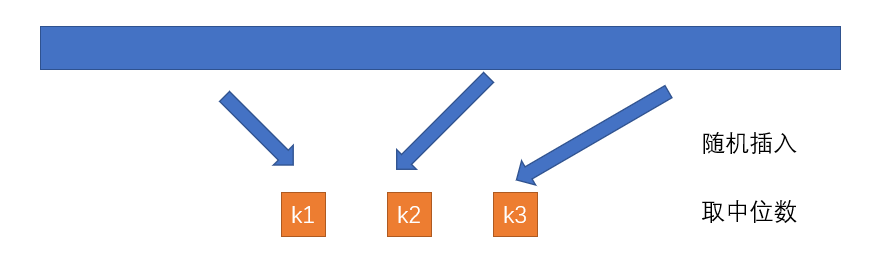
在一般情况下,切分的值都是取的第一个值,这个在遇到一些特殊情况的时候效率较低,所以取数组的中位数来切分才是最好的,但是计算中位数的代价也很高,所以可以从数组中随机取几个值,然后取其中的中位数,来实现,取样的大小可以是3、也可以是5
三向切分
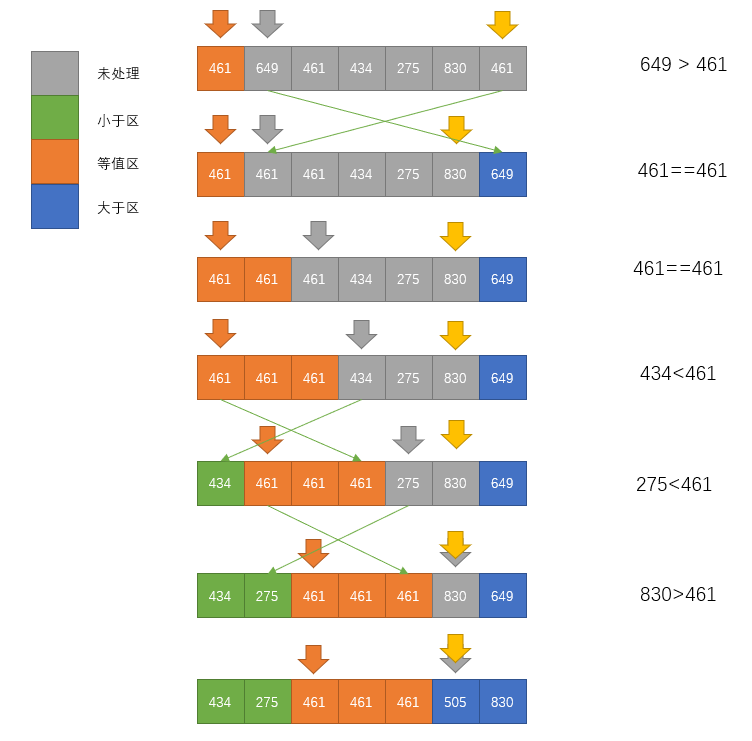
在排序中可能遇到含有大量相等元素的情况,普通的切分方式会对包含有完全相同的数组继续进行递归切分,这部分操作是无意义的,可以通过算法来解决,也就是三向切分的快速排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23function fastSort_3(arr, start = 0, end = arr.length - 1){
if (end - start <= 0) return arr
let k = arr[start]
let left = start, mid = start + 1, right = end
while (mid <= right){
if (arr[mid] < k){
[arr[left], arr[mid]] = [arr[mid], arr[left]]
left++
mid++
} else if (arr[mid] > k){
[arr[right], arr[mid]] = [arr[mid], arr[right]]
right--
} else {
mid++
}
}
fastSort_3(arr, start, left - 1)
fastSort_3(arr, right + 1, end)
return arr
}这个展示的是Dijkstra的解法,感觉类似于冒泡,使用了3个标记来标记位置,其中left标记了小于切分值的数据下一次可以交换的位置,其实也就是切分值数组的左边,而mid则标记的切分值数组的右边,right这是标记的大于切分值的数组的最小边界,用于将扫描到的大于切分值的数据交换过去
算法属性
| 最优时间复杂度 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| Ω(nlogn) | Θ(nlogn) | O(n2) | O(logn) | 不稳定 |
END
2019-02-27 完成
2019-02-25 立项