前端如何优化页面加载速度是很重要的一个工作,提高资源加载速度便是解决方法之一,如何利用好HTTP缓存,便是重中之中,这边文章将讲述HTTP的缓存解决方案
前言
利用浏览器缓存是web优化页面加载速度的一个重要方法,特别是现在前端富应用化越来越严重的情况下,如何高效的利用HTTP缓存是至关重要的,在思考如何构造完善的缓存系统时,了解HTTP缓存的基础是至关重要的
HTTP缓存方式,主要依靠请求头信息来配置,通过是否在下次请求时需要请求服务器可以分为强制缓存和临时缓存
强制缓存
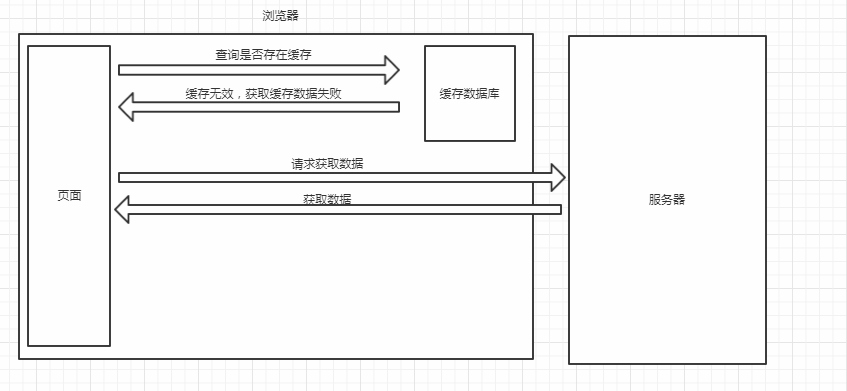
当资源配置了强制缓存的规则后,如果资源发现本地存在有效缓存,那么将会直接应用该缓存
缓存有效时

缓存无效时
Exprise
Expires的值为服务端返回的该资源的到期时间,即下一次请求时,如果请求时间小于服务端返回的到期时间,将直接使用缓存数据。
但是Expires是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。
同时到期时间是由服务端生成的,但是客户端时间可能跟服务端时间存在误差,这就会导致错误的缓存命中。
在HTTP 1.1 的版本,使用了Cache-Control替代。
Pragma
Pragma是HTTP 1.0中控制缓存的方式,在HTTP 1.1中是无效的,可以通过设置为no-cache来禁止缓存
Cache-Control
Cache-Control是HTTP1.1最重要的缓存规则,它控制整个缓存机制的运行,响应的控制字段主要包括max-age、private、public、no-cache以及no-store
| 字段 | 作用 |
|---|---|
| max-age | 在字段设置的时间(秒)后,可以资源可以认定为废弃,在这之前都是可使用的 |
| private | 表示为私有数据,不能被中间服务器(第三方、CND)缓存,是默认的 |
| public | 表示为公有数据,可以被中间服务器(第三方、CND)缓存 |
| no-cache | 表示不能使用强制缓存,需要执行请求进行比对缓存 |
| no-store | 表示不能使用任何缓存,客户端不需要存储该缓存 |
例如max-age=10,表示缓存时间为10秒,在10秒内请求该接口都可以直接从缓存数据库取数据(强制缓存),max-age=10,no-cache,表示缓存时间为10秒的请求需要请进行比对
比对缓存
比对缓存,也就是需要对缓存进行比对来判断是否可以使用该缓存。
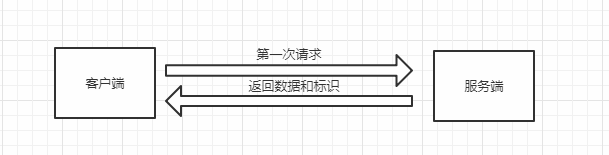
在客户端第一次请求数据时服务端除了数据还会将该数据的标识一同返回给客户端,客户端将标识和数据缓存在本地缓存数据库中,当再次请求数据时,客户端将备份的缓存标识附带在请求当中发送给服务端,服务端会根据标识来判断该请求的结果是否发生了变化,如果没有则响应304,否则正常响应并返回新的数据和标识
第一次请求
后续请求(缓存未变动)
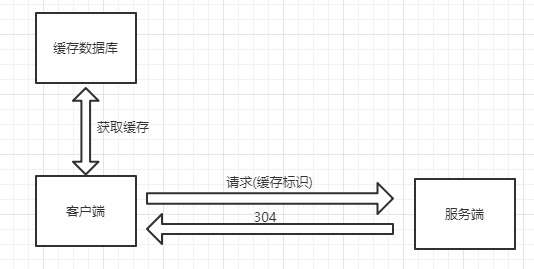
后续请求(缓存改变)

Last-Modified/If-Modified-Since
这组标识对通过修改时间来判断,看名字就知道Last-Modified指的最后的修改时间,If-Modified-Since是询问从哪个时间(获取缓存的最后修改时间)开始是否有修改
Etag/If-None-Match
这组标识通过计算响应数据的摘要,来判断数据是否发送改变,Etag标识的资源的摘要,没有固定的计算要求,客户端只需要将缓存标识原样返回就行了。If-None-Match主要在请求是附带Etag的标识主要用于GET请求,其他特殊请求一般使用If-Match。
其中Etag有强弱之分,例如强缓存为"aabbcc",弱缓存为W/"aabbcc",强弱的控制也是由服务端控制,对于不同强弱可能会采用不同的算法,一般来说强缓存每次文件修改都会要求更新缓存,而弱缓存不会。这个主要解决Last-Modified/If-Modified-Since在某些系统上不能精确到s级以下的问题,而弱缓存则主要防止在一秒多次更新缓存(但数据实时性要求不是很高)
总结
以上便是HTTP缓存相关的信息,这里列举了主要的HTTP请求头、响应头与缓存有关的字段,知道这些字段大致就可以应对大部分的缓存场景了,当然还有一些额外的字段,可以在下方的参考资料,查看规范了解更加详细的内容。
参考资料
END
2018-05-31 完成
2017-08-02 立项

















 ,除了可以改变标题让你的文档更加
,除了可以改变标题让你的文档更加